

Ansiktsdetektering i embeddedtillämpningar
Ansiktsdetektering i realtid och andra vision-tillämpningar är idag fullt genomförbart också i embeddedtillämpningar med storleks- och effektbegränsningar. Eldad Melamed från DSP-företaget CEVA gör här en djupdykning i ämnet och avslutar med ett konstruktionsexempel med ansiktsdetektering baserat på en av företagets vektorprocessorer.
Liksom i det mänskliga visuella systemet utför inbäddade system för datorvision samma visuella funktioner för analys och extrahering av information ur video i en mängd olika produkter.
I bärbara apparater som smartphones, digitalkameror och videokameror måste ökade prestanda kunna levereras, trots begränsningar i storlek, kostnad och effektförbrukning. Bland kommande högvolymmarknader finns fordonssäkerhet, övervakning och spel.
Algoritmer för datorvision identifierar objekt i en scen, och väljer sedan ut en region av en bild som har större betydelse än övriga regioner i bilden. Exempelvis kan objekt- och ansiktsdetektion användas för att förbättra upplevelsen av videokonferenser, hantera publika säkerhetsfiler, återfinna material baserat på innehållet, och mycket mer.
Som svar på marknadens efterfrågan på inbäddade visionsmöjligheter har en industriell allians bildats. Ledda av marknadsundersöksföretaget BDTI består Embedded Vision Alliance (EVA) av 16 medlemmar från IC- och embedded-industrin. De skall ”inspirera och hjälpa embedded-systemkonstruktörer att inkorporera visionsmöjligheter i sina produkter genom att förse dem med praktiska insikter, information och färdigheter”. EVA hoppas att förenkla flödet av högkvalitativ information och insikter om teknologi och trender inom inbäddad vision.
Tillkomsten av EVA är ett bevis på behovet av gott samarbete inom industrin. Men stora framsteg har redan uppnåtts för att förbättra möjligheterna till vision i elektroniksystem. Ett av nyckelkraven är en flexibel bearbetningsarkitektur som kan klara av de omfattande kraven på prestanda och effekt vid mobil bilddetektering och igenkänning i olika produkter.

Fig 1. CEVAs applikation för ansiktsdetektion
Denna artikel presenterar en ansats till en realtidsapplikation för ansiktsdetektion som körs på en programmerbar vektorprocessor. De steg som tas gäller generellt på så vis att de kan användas för att implementera liknande visionsalgoritmer på vilken mobil enhet som helst. I metoden ingår en metod för beskärning och omskalning som kan användas för att korrekt centrera bilden av ett ansikte (se fig 1).
Applikationen kan användas på en enstaka bild eller en videoström, och den har konstruerats för att köras i realtid. Vid ansiktsdetektion i realtid på mobila enheter måste lämpliga implementeringssteg tas för att uppnå ett realtidsflöde.
Utmaningar vid ansiktsdetektion
Medan bearbetning av stillbilder förbrukar små mängder av bandbredd och allokerat minne kan video vara avsevärt mer krävande för dagens minnessystem. Å andra sidan gäller att konstruktion av minnessystem för algoritmer till datorvision kan vara en ytterst stor utmaning på grund av det stora antal bearbetningssteg som krävs för att detektera och klassificera objekt.
Tänk er en 19×19 pixel stor tumnagelbild med ett ansiktsmönster. Det finns 256361 möjliga kombinationer av gråvärden bara för denna lilla bild, vilket kräver en extremt stor dimensionell rymd. På grund av komplexiteten hos ansiktsbilder medför det vissa svårigheter att ge en explicit beskrivning av ansiktsdetaljerna.
Därför har det utvecklats metoder som baseras på statistiska modeller. Dessa metoder betraktar människans ansiktsregion som ett mönster, konstruerar klassificerare genom att träna upp ett stort antal ”ansikte”- och ”icke-ansikte”-sampel och avgör slutligen om bilderna innehåller något mänskligt ansikte genom att analysera mönstret i den detekterade regionen.
Bland övriga utmaningar som algoritmer för ansiktsdetektion måste klara av är poser (framifrån, 45 grader, profil, uppochned), närvaro eller frånvaro av strukturella komponenter (skägg, mustasch, glasögon), ansiktsuttryck, blockering (ansikten kan vara delvis skymda av andra objekt), bildorientering (ansikten ser olika ut vid olika grader av rotation runt kamerans optiska axel) samt bildförhållanden (belysning, kameraegenskaper, upplösning).
Visserligen har många algoritmer för ansiktsdetektion presenterats i litteraturen, men bara en handfull av dem klarar realtidsbegränsningarna i mobila enheter. Många algoritmer har rapporterats generera höga detekteringsgrader, men få av dem lämpar sig för realtidsanvändning i mobila enheter som mobiltelefoner p g a dessa apparaters begränsade beräknings- och minneskapacitet.
Kaskad av klassificerare
Normalt körs realtidsimplementeringar av algoritmer för ansiktsdetektion på PC-plattformar med relativt kraftfulla processorer och mycket minne. En genomgång av befintliga produkter för ansiktsdetektion visar att den algoritm som introducerades av Viola och Jones år 2001 fått stor användning. Detta är ett genombrottsarbete som gör att uppträdandebaserade metoder kan köras i realtid, med samma eller förbättrad noggrannhet.
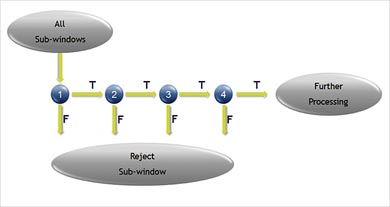
Fig 2. Kaskaden av klassificerare
Algoritmen använder en ”boostad” kaskad av enkla ”features” (detaljer), och den kan delas upp i tre huvudkomponenter:
(1) Integral graf – effektiv konvolution för snabb utvärdering av features.
(2) Användande av Adaboost för att välja ut features och sortera dem efter betydelse. Varje feature kan användas som en enkel (svag) klassificerare.
(3) Användande av Adaboost för att lära upp kaskadklassificeraren (samlingen av svaga klassificerare) som filtrerar ut regioner vilka troligen inte innehåller något ansikte. Fig 2 visar en schematisk representation av kaskaden av klassificerare. Inom en bild är de flesta delbilder instanser av ”icke-ansikte”.
Baserat på detta antagande kan vi använda mindre och mer effektiva klassificerare för att avvisa många negativa exempel under ett tidigt skede, och samtidigt detektera nästan alla positiva instanser. Mer komplexa klassificerare används i ett senare skede för att examinera svåra fall.
Exempel: 24-stegs kaskad av klassificerare
Klassificerare för 2 features i första steget => 60% av icke-ansikten avvisas medan 100% av ansikten detekteras
Klassificerare för 5 features i andra steget => 80% av icke-ansikten avvisas medan 100% av ansikten detekteras
Klassificerare för 20 features i stegen 3, 4 och 5
Klassificerare för 50 features i stegen 6 och 7
Klassificerare för 100 features i stegen 8 till 12
Klassificerare för 200 features i stegen 13 till 24
Under det första steget i algoritmen för ansiktsdetektion kan rektangulära features beräknas mycket snabbt med hjälp av en mellanrepresentation kallad ”integral image”. Som visas i fig 3 är värdet för denna i punkt (x,y) summan av alla pixel ovanför och till vänster. Summan av pixlarna inom D kan beräknas till 4+1-(2+3).
Realtid kräver parallellism
För att kunna implementera en applikation för ansiktsdetektion i realtid i en embedded-applikation behöver vi en hög grad av parallellism, både på instruktionsnivå och datanivå. VLIW-arkitekturer (Very Long Instruction Word) möjliggör en hög grad av samtidig bearbetning av instruktioner, vilket ger utökad parallellism och dessutom låg effektförbrukning.
SIMS-arkitekturer (Single Instruction Multiple Data) gör att en enda instruktion kan operera på flera dataelement, vilket leder till minskad kodstorlek och ökade prestanda. Med en vektorprocessorarkitektur accelereras dessa heltalsberäkningar med en faktor lika stor som antalet parallella adderare/subtraherare. Om ett vektorregister kan laddas med 16 pixlar, och dessa kan adderas till nästa vektor samtidigt, då blir accelerationsfaktorn 16. Att lägga till ytterligare en vektorenhet till processorn fördubblar uppenbarligen denna faktor.
Under de följande stegen av ansiktsdetektion scannas bilden i flera olika positioner och skalor. Adaboost ”strong classifier” (som baseras på rektangulära features) används för att avgöra om sökfönstret innehåller något ansikte eller ej. Även här ger vektoriell bearbetning uppenbara fördelar – möjligheten att samtidigt jämföra flera olika positioner mot ett tröskelvärde.
Med antagandet att i en bild är de flesta delbilderna instanser av icke-ansikte medför fler tillgängliga parallella komparatorer snabbare acceleration.
Antag exempelvis att arkitekturen är uppbyggd så att den under 1 cykel klarar att jämföra 2 vektorer med 8 element i vardera. Då kan 16 positioner av delbilder undersökas under en enda cykel. För att underlätta laddandet av data, och för att utnyttja vektorprocessorn load/store-enhet effektivt, kan positionerna placeras nära varandra.
För att få en höggradigt parallell kod skall arkitekturen stödja prediktering av instruktioner. Det gör att grenar orsakade av ”if-then-else”-villkor kan ersättas med sekventiell kod, vilket minskar antalet cykler och kodstorleken. Med villkorlig exekvering, tillsammans med möjligheter att kombinera villkor, kan man uppnå en högre grad av effektivitet i styrkoden.
Dessutom kan icke-sekventiell kod som grenar och slingor konstrueras utan att det kostar några extra cykler, och detta utan att man behöver ta till besvärliga metoder som dynamiska grenprediktering och spekulativ utvärdering som ökar effektförbrukningen hos RISC-processorer.
Minnesbandbredd
En av de viktigaste utmaningarna i applikationen är minnesbandbredden. Applikationen behöver scanna varje ram i videoströmmen för att kunna utföra ansiktsdetektionen. En videoström kan inte lagras i TCM (tightly coupled memory) p g a den stora datamängden. En HD-ram i formatet YUV 4:2:0 kräver t ex 3 Mbyte dataminne.
Den höga minnesbandbredden orsakar högre effektförbrukning och kräver dyrare DDR-minne, vilket bidrar till att öka komponentkostnaderna. En elegant lösning är att lagra pixlarna med hjälp av ”data tiling”, där 2-dimensionella ”plattor” adresseras från DDR-minnet i en enda skur. Detta ökar i hög grad effektiviteten hos DDR-minnet.
Med DMA (direct memory access) kan dataplattor överföras mellan externt minne och kärnans minnessystem. Under det sista steget i applikationen omskalas den delbild som innehåller det detekterade ansiktet till ett utfönster med fast storlek.

Fig 3. Snabb utvärdering av rektangulära features med hjälp av ”integral image”
Processen med omskalning av bilder används även under detekteringsfaserna om bilden scannats med olika skalor. Algoritmer för omskalning används i stor utsträckning inom bildbehandling för upp- och nedskalning av video. Algoritmen som implementerats i denna applikation är bi-kubisk.
Vid kubisk konvolutionsinterpolation bestäms gråvärdet ur det vägda medelvärdet av de 16 närmaste pixlarna till de specificerade inkoordinaterna, och utkoordinaterna tilldelas detta värde. Först utförs endimensionella kubiska konvolutioner i en riktning (horisontellt), och sedan utförs sådana i vinkelrät riktning (vertikalt). Det betyder att för att implementera en tvådimensionell kubisk konvolution behövs det bara en endimensionell kubisk konvolution.
Flexibla bearbetningsmöjligheter
En vektorprocessorkärna som har kraftfulla ladda/lagra-möjligheter för att snabbt och effektivt kunna adressera data är en absolut nödvändighet för sådana applikationer, där algoritmerna opererar på datablock. Optimeringen av omskalningsalgoritmen kan klaras av om det finns möjlighet att adressera 2-dimensionella minnesblock från minnet i en enda cykel.
Detta gör att processorn effektivt kan uppnå hög minnesbandbredd utan att behöva ladda onödiga data eller belasta beräkningsenheterna med att utföra datamanipulationer.
Dessutom är möjligheten att låta datablock byta plats under dataaccess och utan några extra cykler – vilket gör att ett flyttat block kan adresseras i en enda cykel – en ytterst praktisk egenskap vid implementeringen av de horisontella och vertikala filtren. Processorns kraftfullhet är beroende av hur den kan utföra kraftfulla konvolutioner, där parallella filter kan arbeta i en och samma cykel.
Ett exempel på en effektiv lösning är att ladda 4×8 byte stora block i en enda cykel, och sedan utföra den kubiska konvolutionen i vertikal riktning med 4 pixlar per iteration. De 4 pixlarna har förbeställts i 4 separata vektorregister, så vi kan få 8 resultat samtidigt.
Dessa mellanresultat bearbetas på exakt samma vis, men med data laddade i omkastat format, för att utföra den horisontella filtreringen. För att kunna bevara resultaten korrekt krävs det en initiering med ett avrundningsvärde och en efterskiftning av resultatet. Filterkonfigurationen bör möjliggöra dessa aktiviteter utan att det krävs någon speciell instruktion.
Totalt kan denna typ av kärna för parallell vektorbearbetning balanseras mellan operationer hos load/store-enheten och hos bearbetningsenheterna. Generellt medför begränsningar i databandbredd, liksom kostnaden för bearbetningsenheter vad gäller effektförbrukning och chipyta, restriktioner för implementationens effektivitet. Men det är tydligt att en avsevärd acceleration uppnås, jämfört med skalära processorarkitekturer.
Plattform för HD-video
CEVA tillhandahåller en bearbetningsplattform som uppfyller behoven för en sådan vision-applikation.CEVA-MM3000 är en skalbar, fullt programmerbar multimediaplattform som kan integreras i ett SoC för att i formatet 1080p/60fps klara videokodning och -avkodning, ISP-funktioner och vision-applikationer, helt i mjukvara.
Plattformen består av två specialprocessorer – en Stream Processor och en Vector Processor – som kombineras till ett komplett, flerkärnigt system, inklusive lokalt och delat minne, periferifunktioner, DMA och standardbryggor till externa bussar. Plattformen har konstruerats specifikt för att uppfylla kraven på låg effektförbrukning i mobila enheter och annan konsumentelektronik.
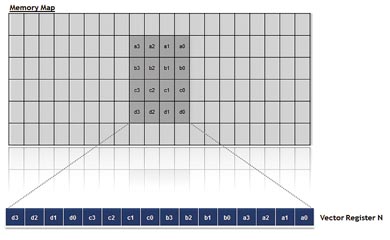
Fig 4. Laddning av ett 4×4-block av pixlar
Vektorprocessorn innehåller två oberoende VPUer (vector processing units), som tar hand om alla vektorberäkningar. Här ingår både inter-vektor-operationer (som arbetar med SIMD) och intra-vektor-operationer. Inter-vektor-instruktioner kan operera på sexton 8-bits element (byte) eller åtta 16-bits element (word), och de kan använda vektorregister parvis för att forma 32-bits element (double-word). VPUn klarar att utföra åtta parallella filtreringar om sex "taps" vardera under en enda cykel.
Medan VPUerna fungerar som beräkningsarbetshästar för Vector Processorn, arbetar VLSU-enheten (Vector Load and Store Unit) som fordonet för överföring av data från/till Data Memory Sub-System till/från Vector Processorn. VLSUn har 256-bits bandbredd för både laddnings- och lagringsoperationer, och den stöder ”non-aligned” accesser. Enheten klarar att adressera 2-dimensionella datablock i en enda cykel, med stöd för olika blockstorlekar.
För att underlätta VPUernas arbete kan VLSU flexibelt manipulera datastrukturen vid läsning/skrivning av vektorregister. Ett datablock kan växla position under dataaccesser utan att några extra cykler krävs, vilket gör att ett flyttat block kan adresseras i en enda cykel.
Växlingsfunktionen kan kopplas in eller ut dynamiskt. Det gör att samma funktion kan återanvändas för både horisontella och vertikala filter. Detta sparar in utvecklings- och avbuggningstid för varje filter, och reducerar samtidigt progamminnets storlek.
Eldad Melamed, CEVA
Om författaren
Eldad Melamed blev M Sc vid Weizmann Institute of Science i Israel år 2000, och B Sc i kemi vid Techinion, Israel Institute of Technology år 1994. Han är projektchef på CEVAs avdelning för videoalgoritmer. Under åren 2000 till 2002 var han algoritm- och mjukvaruingenjör på Meicom Technologies. Han innehar ett flertal patent.
Filed under: Embedded




