

Accelerera OpenCV i FPGA med inbäddad vision
OpenCV är ett kraftfullt bibliotek med funktioner för datorvision. Funktionerna används idag flitigt i branschen. Precis som andra projekt med öppen källkod utvecklas och förbättras algoritmerna hela tiden av de användare som ingår i gemenskapen. Idag finns mer än 2 500 funktioner tillgängliga. Fernando Martinez Vallina och José Roberto Alvarez från Xilinx beskriver här hur det fungerar.
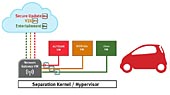
Med tekniker som OpenCV ser vi en växande tendens att bädda in videoanalys – eller Smart Vision-funktioner – i de videonät som idag blir alltmer mångsidiga och används t ex som förarhjälpmedel i bilar samt i säkerhetssystem för företag och hushåll. I takt med att bildsensorernas upplösning förbättras ökar också de möjligheter som mer avancerad bildbehandling innebär, något som ger upphov till nya säkerhetsfunktioner.
Av logistiska och databeräkningsskäl är det i regel bäst att bädda in dessa funktioner där inspelningen sker, alltså i själva kameran. Videoanalysfunktionerna är dock kända för att vara resursslukande, även om de utformats för att vara extremt portabla och effektiva när de körs i vanliga multiprocessorsystem. Det här betyder att inbäddade system, som alltså har jämförelsevis begränsade resurser, inte alltid kan tillhandhålla den processorkraft som krävs för att hantera de krav i realtid som de stora bildstorlekarna och höga bildrutehastigheterna ställer i dagens Smart Vision-system.
Rörelseavkänning
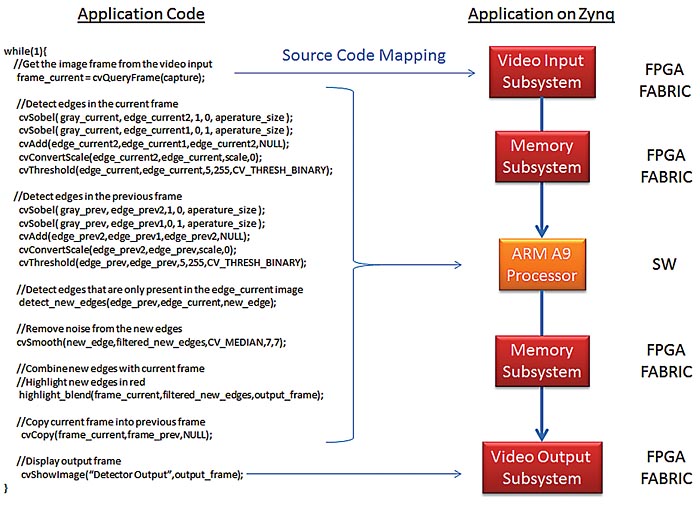
En typisk tillämpning är rörelseavkänning, där flera bildrutor i följd jämförs för att identifiera objekt som rör sig i synfältet. I Fig 1 visas ett sådant system.
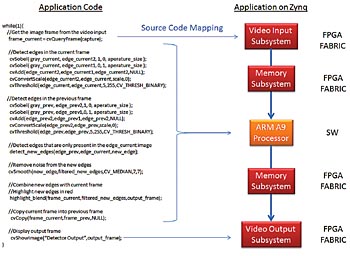
Fig 1. Exempel på rörelseavkänning med hjälp av OpenCV-algoritmer
Klicka här för större bild
Det första stadiet är en algoritm framtagen för att detektera kanterna på objekt, en metod som minskar datamängden i varje bildruta. Så snart kanterna identifierats gör jämförelser mellan bildrutorna att rörliga objekt markeras, så att man får en maskbild för rörelseigenkänning. Slumpmässigt brus från sensorn kan orsaka fel mellan bildrutorna och måste därför filtreras bort.
I det här exemplet avlägsnas bruset med ett 7×7-medianfilter på maskbilden för rörelseavkänning. Grundfunktionen i ett sådant medianfilter är att beräkna medelvärdet för ett 7×7-fönster med närliggande pixlar och sedan använda det som slutvärde för fönstrets mittpixel. Efter brusreduceringen kombineras masken för rörelseigenkänning med den ingående rörliga bilden så att kanterna på objekt som rör sig markeras.
Algoritmer i C++
Eftersom algoritmerna är skrivna i C++ kan den här exempeltillämpningen implementeras på en processorplattform som t ex ARM Cortex-A9 med två kärnor (som finns i Zynqs programmerbara SoC), med en del funktioner implementerade i FPGA-lagret. I det här exemplet är de enda funktioner som portas till FPGA-lagret de två I/O-funktionerna för video cvgetframe och showimage, som både använder I/O-undersystemen Xilinx för video.
När funktionen cvgetframe anropas fångar datasidan i I/O-undersystemet för video in och avkodar en videoström från ett HDMI-gränssnitt och förser DDR-minnet med pixeldata. Funktionen showimage hanterar överföringen av pixeldata från DDR-minnet till en bildskärms kontrollenhet. Observera att den här implementeringen ger en bildrutehastighet på endast 1 ny bildruta vare 13:e sekund (motsvarande 0,076 bildrutor i sekunden).
För att maximera prestanda är systempartitionering ett viktigt steg i utvecklingsprocessen. Eftersom OpenCV-biblioteket är skrivet på högnivåspråket C++ kan alla dess funktioner kompileras för att köras på en- eller flerkärniga processorer såsom de som ingår i Zynq SoC, som tidigare angetts. Genom att utföra en prestandaanalys kan tekniker avgöra vilka delar av algoritmen som kan avlastas med accelerationsblock i maskinvaran – som t ex implementeras i Zynqs FPGA-lager – för att uppfylla prestandamålen i realtid.
Sådan maskinvaruacceleration ger visserligen bättre prestanda men den kan också vara en utmaning för designen; OpenCV-biblioteken från Xilinx har optimerats och förberetts för dess syntesmiljö på hög nivå – Vivado HLS – och stödjer därmed funktioner som kan hantera pixelbehandling vid en upplösning på 1080 p.
Maskinvaruacceleration
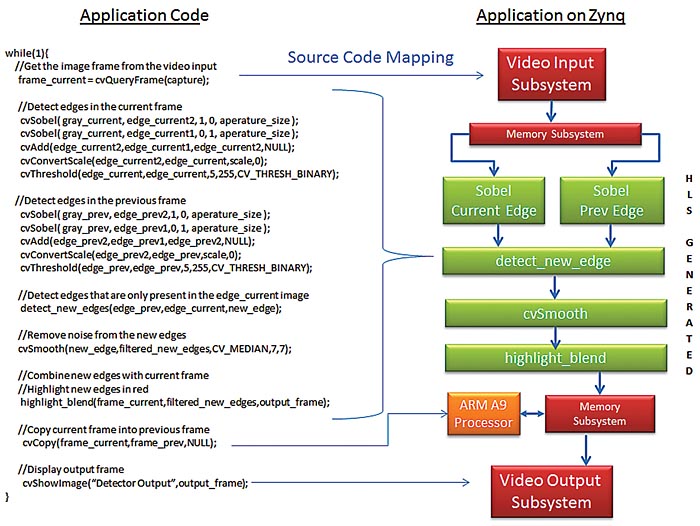
Det optimerade OpenCV-biblioteket implementerar grundläggande funktioner med hjälp av maskinvaruacceleration, samtidigt som det tillåter att samma högnivådesign som i exemplet ovan används. Tack vare att databehandlingen sker via Vivado kan samma design som kompilerats för Zynq SoC ge realtidsprestanda på 60 bildrutor/s, vilket visas i Figur 2.
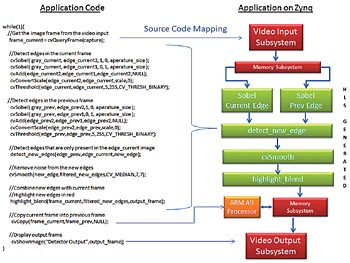
Fig 2. Exempel på rörelseavkänning som körs på Zynq SoC med maskinvaruacceleration och programmerbart lager
Klicka här för större bild
Som framgår används här samma mappingfunktioner för video-I/O, men de kompletteras av algoritmens beräkningsmässiga kärna som nu har kompilerats till flera IP-block genererade av Vivado HLS. Dessa block, som kopplas till I/O-undersystemet för video via Vivado IP Integrator, har optimerats för en videobehandling i upplösningen 1080 p och med hastigheten 60 bildrutor i sekunden.
Den bästa och mest beprövade lösningen för att implementera de senaste visionsfunktionerna för datorer är att använda OpenCV-biblioteken med öppen källkod. Dessa bibliotek, som är skrivna på C++, kan nu också på ett effektivt sätt översättas till RTL om man vill skapa maskinvaruacceleratorer lämpliga att använda i ett FPGA-lager samtidigt som man behåller den flexibilitet och metodik som utmärker OpenCV-projekt.
Fernando Martinez Vallina, HLS Design Methodology Engineer, och José Roberto Alvarez, Engineering Director, for Video Technology Xilinx Inc
Filed under: FPGA





{kind=link}
{kind=link}