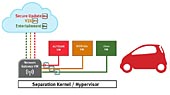


Datainsamling och stora datamängder
Derrik Snyder från National Instruments skriver här om hur det inte längre handlar om att samla in så mycket data som möjligt utan om att snabbt få fram det som är intressant ur de stora datamängderna.
En gång i tiden var det datainsamlingshastigheten som begränsade de datamängder som gick att samla in. Det var A/D-omvandlarna som satte gränsen.
Idag har hårdvaruleverantörerna höjt datainsamlingshastigheten och passerat de tidigare begränsningarna av hastighet och noggrannhet, vilket har fått nya konsekvenser för datahanteringen. Enkelt uttryckt är det inte längre hårdvaran som är den begränsande faktorn i datainsamlingsapplikationer, utan det växande problemet är hur man ska hantera alla insamlade data.
Mikroprocessorn banade väg
Utvecklingen inom datorteknik – inbegripet mikroprocessorernas högre hastigheter och lagringsmediernas större kapacitet – i kombination med minskande kostnader för hårdvara och mjukvara har medfört en explosion av data som kommer in i rasande fart. Särskilt i mätapplikationer kan man samla in väldiga mängder data varje sekund varje dag. Varje sekund som Large Hadron Collider vid CERN kör ett experiment ger den upphov till 40 terabyte data. Varje halvtimme som en jetmotor från Boeing körs genererar systemet 10 terabyte driftinformation. Under en tur över Atlanten kan en fyrmotorig jumbojet skapa 640 terabyte data. Multiplicerar man det med över 25 000 flygturer varje dag, får man en uppfattning om vilka enorma datamängder som genereras (Gantz 2011). Här snackar vi “stora datamängder“.
Teknikforskningsföretaget IDC genomförde nyligen en studie om digitala data, vilket innefattar hela världens mätfiler, videofiler, musikfiler osv. I studien uppskattas att mängden tillgängliga data fördubblas vartannat år. Att dataproduktionen dubbleras vartannat år liknar en av elektronikens mest kända lagar, nämligen Moores lag. År 1965 konstaterade Gordon Moore att antalet transistorer i en integrerad krets fördubblades ungefär vartannat år, och han räknade med att detta skulle hålla i sig ”i åtminstone tio år”. Fyrtioåtta år senare påverkar Moores lag fortfarande mycket inom informationsteknik och elektronik. Om produktionen av digitala data fortsätter enligt Moores lag, kommer en organisations framgång att vara beroende av hur snabbt insamlade data kan omvandlas till användbar information.
De stora datamängderna innebär nya utmaningar när det gäller dataanalys, sökning, integration, rapportering och systemunderhåll, som alla måste hålla jämna steg med den exponentiella tillväxten av data.
Datakällorna är många. Bland de intressantaste för ingenjörer och forskare är de data som kommer från fysikaliska fenomen. Det är analoga data som är insamlade och digitaliserade och alltså kan kallas ”Big Analog Data™” (”Stora Analoga Datamängder”). De kommer från mätningar av vibrationer, RF-signaler, temperatur, tryck, ljud, bilder, ljus, magnetism, spänning osv. De problem som är specifika för stora analoga datamängder har gett upphov till tre tekniktrender inom det breda området datainsamling.
Sammanhangsbaserad datasökning
De fysikaliska egenskaperna hos vissa företeelser gör att man inte kan få fram den intressanta informationen om inte insamlingshastigheten är mycket hög, vilket även medför stora datamängder. Att nöja sig med mindre datamängder än vad som vore möjligt att samla in kan också begränsa noggrannheten i slutsatser och förutsägelser. Tänk på en guldgruva där bara 20 procent av guldet är synligt och 80 procent ligger i gruset där det inte går att se. Vid mineralutvinning måste man inse vilket totalvärde som finns i gruvan. ”Digitalt grus” är digitaliserad data som kan innehålla värdefull information som man inte ser. Alltså behövs ”datautvinning” och analys för att man ska få fram ny fakta som man tidigare inte upptäckt.
Datautvinning innebär att man använder sammanhangsinformation som sparats tillsammans med data när man söker igenom och skalar ner stora datamängder till mer hanterbara volymer. Om man lagrar rådata ihop med uppgifter om det ursprungliga sammanhanget, eller metadata, blir data enklare att gruppera, hitta och senare bearbeta och förstå. Se till exempel på en följd av till synes slumpmässiga siffror: 0858789500. Vid ett första ögonkast är det omöjligt att få ut något av värde ur dessa rådata, men i sitt sammanhang – 08-587 895 00 – är siffrorna mycket enklare att känna igen och tolka som ett telefonnummer. Beskrivande information om mätdatas sammanhang ger motsvarande fördelar och kan specificera allt från sensortypens tillverkare eller kalibreringsdatum för en given mätkanal till version, konstruktör eller testobjektets modellnummer. Ju fler kringuppgifter som sparas tillsammans med rena mätdata, desto lättare kan informationen spåras under hela livscykeln, sökas, lokaliseras och i framtiden korreleras med andra mätningar av särskild efterbehandlingsmjukvara.
Intelligenta datainsamlingsnoder
Datainsamlingsapplikationer är väldigt olika och används i många branscher, men sällan eller aldrig samlas data in för sin egen skull. Ingenjörer och forskare bygger avancerade insamlingssystem, men de rådata som systemen producerar är inte slutmålet. Rådata samlas in så att den kan användas som utgångsdata för analys eller bearbetning och leda fram till sådana resultat som systemkonstruktörerna strävar efter. Till exempel kan man vid krocktester samla in gigabyte av data på några få tiondels sekunder och få fram värden på hastigheter, temperaturer, stötkrafter och acceleration. En av de viktiga saker som kan beräknas utifrån denna rådata är skallskadefaktorn (Head Injury Criterion, HIC), ett enda tal som räknas fram och anger sannolikheten för att en testdocka ska råka ut för en skallskada vid krocken.
Utöver det kan vissa applikationer – särskilt inom miljö-, byggnads- och maskinövervakning – arbeta med periodisk insamling av data med en låg hastighet men som kan öka drastiskt och ge data i skurar när något anmärkningsvärt upptäcks. Den här tekniken innebär att insamlingshastigheterna normalt är låga och att man loggar minimalt med data men möjliggör höga insamlingshastigheter som räcker till insamling av snabba vågformer när så behövs i applikationerna.
För att omedelbart bearbeta rådata till resultat eller ändra mätförfarandet när vissa kriterier uppfylls, måste man lägga in intelligens i datainsamlingssystemet.
Det är vanligt att överföra testdata till en dator (”intelligensen”) via standardbussar som USB och Ethernet, men mätningar på många kanaler med höga samplingshastigheter kan lätt göra att kommunikationsbussen blir överbelastad. Ett alternativ är att lagra data lokalt och överföra filerna för bearbetning när testet har körts klart, men det förlänger tiden det tar att få fram användbara resultat. För att adressera sådana problem innehåller de senaste mätsystemen ledande teknik från ARM, Intel och Xilinx och kan därigenom erbjuda högre prestanda och bearbetningskapacitet, samt standardkomponenter för både mellanlagring och snabb dataöverföring till disk. Processorer på korten gör att intelligensen har blivit mer decentraliserad, eftersom bearbetningselementen sitter närmare sensorn och själva mätningen. Modern datainsamlingshårdvara innehåller snabba flerkärneprocessorer som kan köra insamlingsmjukvaran och beräkningsintensiva analyser och algoritmer parallellt med mätningarna. De här intelligenta mätsystemen kan analysera och leverera resultat snabbare utan att behöva vänta ut överföring av stora datamängder – eller att först behöva logga dem – vilket optimerar systemet så att det använder diskutrymmet effektivare.
Derek Snyder, National Instruments, produktmarketing manager med specialisering på hårdvara för datainsamling.
Bearbetning och lagring i molnet
Derek Snyder hänvisar till nedanstående artikel som är ett bidrag från Amazon Web Services, skriven av Matt Wood, Senior Manager and Principal Data ScientistKombinationen av datainsamlingshårdvara och intelligens på kortet har gjort att systemen i ökande grad kan byggas in eller användas på distans och har inom många områden berett vägen för helt nya applikationer. Det har gjort att ”Apparaternas Internet” har börjat utvecklas mitt framför ögonen på oss, eftersom den fysiska världen är full av intelligenta apparater och människan nu kan samla in mängder av data om snart sagt allt i hennes omgivning.
Möjligheten att bearbeta och analysera alla nya data som innehåller information om den fysiska världen kommer att få djupgående inverkan inom många områden. Från hälsovård till energiproduktion, från transporter till träningsutrustning och från automatisering till försäkringar – möjligheterna är praktiskt taget obegränsade.
I de flesta av ovan nämnda branscher är det inte insamlade data som är problemet. Det finns gott om duktigt folk som samlar in massor av värdefulla data. Hittills har detta i huvudsak varit ett IT-problem.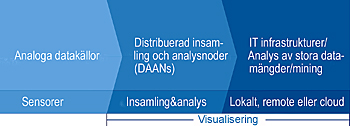
”Internet of things”
Apparaternas Internet ger upphov till väldiga mängder data från fjärrutrustning i fält som bokstavligen är utspridda över hela världen, ibland i de mest avlägsna och ogästvänliga av miljöer. Dessa utspridda insamlings- och analysnoder som är inbyggda i andra slutprodukter är i själva verket datorsystem med mjukvaror som ofta är kopplade till flera datornätverk parallellt. De utgör några av de mest komplicerade distribuerade systemen och genererar de största datamängder som världen någonsin skådat. De här systemen behöver:
1) nätbaserade verktyg för systemunderhåll på distans för automatisering av konfigurering, underhåll och uppdatering av insamlings- och analysnoderna och
2) ett sätt att effektivt och kostnadseffektivt bearbeta alla data.
Något som komplicerar saken är att om man reducerar den traditionella IT-topologin hos de flesta organisationer som samlar in sådana data till en enkel form, finner man att de i själva verket använder två parallella nätverk med distribuerade system: dels ”nätverket för de inbyggda systemen” som är anslutet till alla fältenheterna som samlar in data, dels det ”traditionella IT-nätverket” där den mest värdefulla dataanalysen implementeras och distribueras till användarna. Oftast är det inom organisationerna ett stort glapp mellan de båda parallella nätverken, och de kan inte samverka. Det gör att data inte kan läggas där den skulle komma till störst nytta.
Tänk vilken styrka ett olje- och gasföretag skulle kunna uppnå genom att samla in realtidsdata om hur mycket olja som kommer upp ur marken och transporteras genom en rörledning i Alaska och sedan kunde överföra dessa data till bokföringsavdelningen, inköpsavdelningen, transportavdelningen och ekonomiavdelningen – som alla finns i Houston – inom några minuter i stället för att det ska dröja dagar eller månader.
Lagra data i molnet
De parallella nätverken inom organisationerna och de stora investeringar som gjorts i dem har tidigare varit de största hindren för Apparaternas Internet. Men dagens molnbaserade datalagring, beräkningskraft och verktyg för hantering av stora datamängder svarar upp mot utmaningarna.
Det är enkelt att med molnlagring och molnets beräkningsresurser skapa en gemensam samlingsplats för data som kommer från ett stort antal inbyggda enheter (till exempel utspridda insamlings- och analysnoder) och ge vilken grupp som helst inom organisationen tillgång till dessa data. Det löser problemet med de två parallella nätverken som inte fungerar tillsammans. Att ge användarna tillgång till molnets nästan oändliga lagrings- och beräkningsresurser så att de kan utnyttjas direkt och debiteras vid behov ger lösningar till utmaningen att hantera distribuerade system och bearbeta väldiga mängder insamlade mätdata.
Tre stora fördelar
Sammanfattningsvis erbjuder molntekniken tre stora fördelar för hantering av distribuerade system och tillgång till data:
* Datalagring: Om avståndet mellan de olika elementen i systemet uppgår till kilometer i motsats till millimeter, kan det vara klokt att överväga datalagring i molnet. Om man till exempel ska övervaka i vilket skick alla växellådorna är i en vindkraftspark med hundratals turbiner kan datainsamlingen bli oerhört dyr och besvärlig. Med lagring i molnet kan sådana system ha data på en gemensam plats så att man enkelt kan samla in, analysera och jämföra uppgifterna.
* Tillgång till data: I en del fall är det inbyggda datainsamlings- eller övervakningssystemet som ska konstrueras svårt att nå fysiskt. Om man till exempel ska övervaka i vilket skick en rörledning är i en avlägsen del av Alaska, vill man inte behöva skicka en tekniker för att logga informationen och kontrollera systemets status. Om dessa data lagras i molnet kan man komma åt dem från vilken plats som helst, exempelvis från persondatorer och mobila enheter.
* Avlastning: De nästan oändliga beräkningsresurserna i molnet kan avlasta programvarans tunga beräkningar. Det kan vara avancerad bild- eller signalbehandlingar eller till och med kompilering och utveckling.
Filed under: Matteknik




