

Visualisering förenklar RTOS-felsökning
De flesta som utvecklar mjukvara har nog hört (eller använt) uttrycket ”det är ingen bug, det är en feature”. Det må vara oklart varifrån detta uttryck härstammar, men innebörden är tydlig – ett tvivelaktigt beteende i programvaran.
Johan Kraft, CEO och grundare av svenska Percepio AB, visar i den här artikeln hur man med grafisk visualisering kan lösa problem som bottnar i feltänk, snarare än felaktig kod.

Dr Johan Kraft, CEO, Percepio AB
Den här typen av ”features” i ett inbyggt system kan komma från hårdvaran eller mjukvaran, men syns ofta bara när vissa villkor sammanfaller. I hårdvaruvärlden handlar det ofta om timing på nanosekundnivå, men så länge signalen är fysiskt tillgänglig så finns det bra instrument som kan mäta och visualisera med hög upplösning. I mjukvaruvärlden är det svårare.
Multitrådning
Även om flerkärniga processorer blir allt vanligare så är enkelkärniga processorer fortfarande dominerande inom inbyggda system. För att kunna hantera flera parallella aktiviteter, t ex nätverkskommunikation och signalbehandling, används så kallad multitrådning med hjälp av ett operativsystem, ofta ett realtidsoperativsystem (RTOS). Dessa har förutsägbart och snabbt beteende, och kompileras ner till några kilobyte objektkod. Genom ett RTOS kan programvaran delas upp i separata trådar för varje aktivitet (”task”), som exekverar till synes parallellt och oberoende på samma processorkärna.
Detta är möjligt genom operativsystemets mest centrala funktion, schemaläggaren, som periodiskt kontrollerar trådarna och bestämmer vilken tråd som ska köra i nästa tidsintervall, baserat på deras prioritet och status. Om ett annat task med högre prioritet är redo att exekvera så görs ett task-byte, genom att spara tillståndet för det tidigare tasket (register, stackpekare m m) och därefter läsa in det senaste tillståndet för det nya tasket.
I ett RTOS körs schemaläggaren ofta med hög frekvens (1 kHz eller mer) för att ge tasken ett exakt tidsbeteende. Schemaläggaren i ett RTOS är i allmänhet minimal, högoptimerad och mycket snabb. Vissa tvekar att använda ett RTOS i tron att schemaläggningen ska kosta mycket processortid, men ett RTOS ger normalt sett ingen märkbar prestandaförlust på en 32-bitars processor. Tvärtom kan ett RTOS ofta ge ett effektivare system då processortiden kan utnyttjas effektivare. Tasks kan vänta på input utan att använda processortid, för att sedan aktiveras av operativsystemet när rätt villkor uppnåtts. En annan fördel är att koden kan göras mer modulär jämfört med en traditionell ”super-loop”, vilket förenklar vidareutveckling och underhåll. Med ett RTOS kan också undvika överdrivet långa avbrottsrutiner, genom att i stället använda ett task som aktiveras av avbrottsrutinen. Då kan andra avbrott behandlas under tiden som tasket exekverar, vilket ger bättre responsivitet.
Multitrådning genom ett RTOS möjliggör alltså högre effektivitet och flexibilitet, men multitrådning kan även medföra högre komplexitet, eftersom tasks inte är helt oberoende utan måste dela på hårdvarans resurser, t ex processortid och arbetsminne, samt kommunicera med varandra. I värsta fall kan det uppstå buggar som endast visar sig under vissa speciella förhållanden. Utan insyn i den detaljerade exekveringen kan felsökning av multitrådade system bli tidsödande och kostsam.
Ett typiskt exempel är oväntade fördröjningar i exekveringen av ett periodiskt task, t ex en reglerfunktion. Ett realtidsoperativsystem ska ju ge ett förutsägbart tidsbeteende, men detta är beroende av applikationskoden. En av våra kunder beskrev ett fall där systemet skulle läsa av en sensor var 5:e millisekund, men i vissa fall var det uppåt 6,5 ms mellan läsningarna, utan någon uppenbar orsak till detta
I ett annat kundfall hade de problem med att systemet i vissa fall startade om på grund av en ”watchdog reset”, men det var svårt att förstå varför. I ett tredje kundfall noterades att svarstiden på nätverksmeddelanden hade ökat kraftigt i senaste bygget, trots att kodändringarna var små och till synes irrelevanta. Detta är tre exempel på hur oväntat beteende kan uppstå i inbyggd programvara, där utvecklarna ofta måste gissa och prova sig fram till lösningar utan att egentligen förstå grundproblemet. Detta är ineffektivt och ofta kan man inte vara säker på att grundproblemet verkligen är löst.
Inspelning och visualisering
För att förstå vad som händer i ett multitrådat system behövs en inspelning (”trace”) som visar relevanta händelser (t ex task-byten) och tidpunkten de inträffat. Att spela in programvara är verkligen inte något nytt. Det har man gjort i princip så länge det funnits datorer i syfte att t ex felsöka eller optimera ett program. Men även om en RTOS-inspelning innehåller rätt information är det ofta svårt att förstå och överblicka informationen eftersom den är så omfattande och merparten är dessutom irrelevanta upprepningar. Nyckeln är specialutvecklad visualisering som tillåter analys från olika perspektiv och på olika abstraktionsnivåer. Detta gör det möjligt att förstå det övergripande beteendet och hitta avvikelser från detta.
Det klassiska sättet att visualisera en RTOS-inspelning är en horisontell tidslinje som visar exekveringen av tasks, ofta utökad med ikoner för att indikera andra händelser. Nackdelen med detta upplägg är det ofta blir hundratals olika ikoner, som kan vara svårt att memorera. Ett annat upplägg används i Tracealyzer från Percepio AB. Tidslinjen är i stället vertikal (se fig 1) med horisontella etiketter som visar händelser med namnen i klartext. Etiketterna är dessutom färgkodade med en handfull tydliga bakgrundsfärger, t ex används röd färg för RTOS anrop som blockerar och orsakar ett task-byte.
Specialutvecklad visualisering möjliggör dessutom smarta funktioner som underlättar förståelsen. Om användaren t ex markerar en blockerande händelse (en röd etikett), så markerar Tracealyzer automatiskt även motsvarande punkten där tasket vaknar upp (grön etikett). På liknande sätt kan man se vilken händelse som aktiverade ett task vid ett visst tillfälle, samt spåra individuella meddelanden som skickas mellan tasks.
Tracealyzer erbjuder också flera andra vyer med horisontella tidslinjer som kan kombineras på en gemensam tidsskala, t ex processorbelastning, minnesanvändning och svarstider. På så vis framträder eventuella samband mellan de olika perspektiven, vilket kan ge ledtrådar.
Det är också värdefullt om utvecklare kan utöka en inspelning med egen loggning. Detta ger möjlighet att visualisera valfria händelser och data från applikationskoden tillsammans med operativsystemets exekvering och tjänster. Data som bifogas sådana händelser kan även visualiseras som diagram, vilket kan användas för att analysera t ex regleralgoritmer. I exemplet från Tracealyzer visas applikationsloggning (”User Events”) med gula etiketter. Denna typ av loggning är mycket snabb då formateringen görs i efterhand av visualiseringsverktyget, till skillnad från den klassiska ”printf” funktionen i C som kräver avsevärt fler processorcykler och stack. Därmed kan man logga utan märkbar påverkan på realtidsbeteendet, även i tidskritisk kod som t ex avbrottshanterare.
Exempel
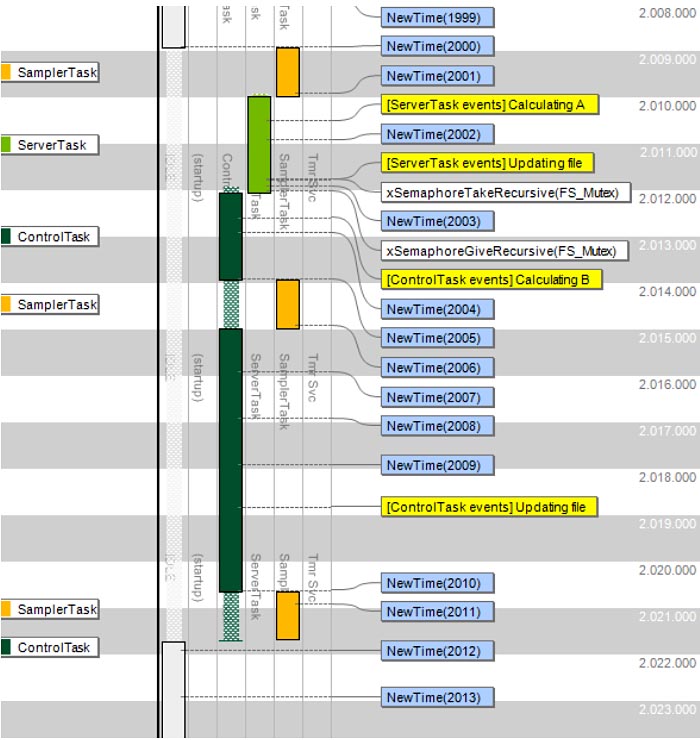
Här följer några konkreta exempel som visar hur visualisering kan förenkla felsökning av RTOS-baserad programvara. fig 1a visar en situation där ett task kallat ”SamplerTask” blir oväntat fördröjt, här illustrerat med Tracealyzers vertikala tidslinje. Detta task är avsett att exekvera periodiskt var femte millisekund, men med Tracealyzer kan vi se att tiden mellan körningarna ibland avviker från detta och det kan vara uppåt 6,5 millisekund. I fig 1a kan vi även se orsaken.
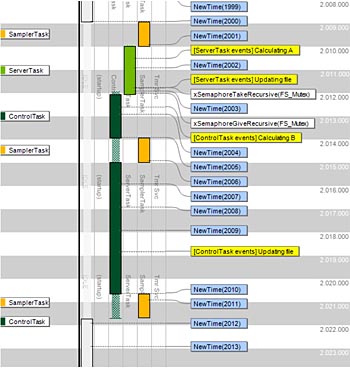
Fig 1a. Oväntad fördröjning av periodiskt task, antagligen pga avstängda avbrott (klicka för större bild )
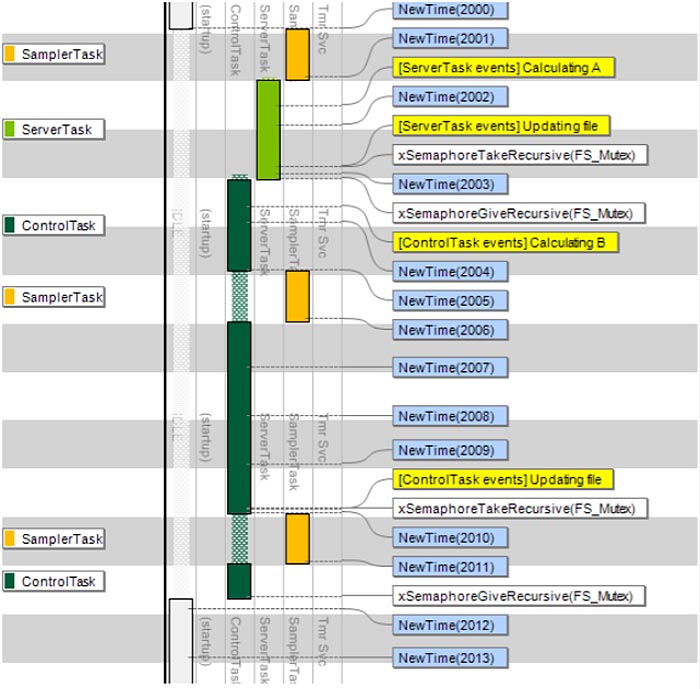
Händelserna benämnda ”NewTime” i fig 1a skapas av operativsystemets schemaläggare vid varje periodisk kontroll (OS tick), i detta fall normalt sett varje millisekund. Här finns dock intervall på flera millisekunder utan sådana händelser. Detta innebär att operativsystemets schemaläggare varit periodvis avstängd, antagligen på grund av ”ControlTask” som exekverar vid varje sådant intervall i inspelningen. Vid analys av dess kod upptäcktes att avbrotten stängdes av under en filsystemsoperation, en s k ”kritisk sektion” som skyddades genom att helt stänga av avbrott och därmed också schemaläggaren. En Mutex är dock ett bättre sätt att skydda en kritisk sektion, då det inte stänger av hela operativsystemet utan låter orelaterade exekvera ostört (som SamplerTask i detta fall). Alla RTOS erbjuder Mutex eller liknande funktioner. När utvecklaren ändrade koden till att använda en Mutex försvann problemet. Nu exekverar SamplerTask med perfekt periodicitet på 5 millisekunder, som illustrerat i fig 1b.
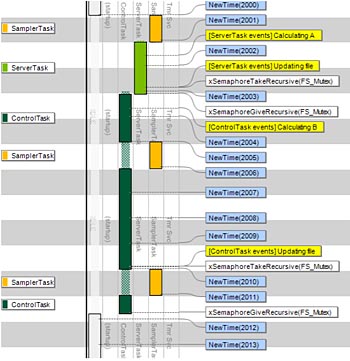
Fig 1b. Inga fördröjningar med Mutex i stället för avstängda avbrott (klicka för större bild)
Nästa exempel illustrerar hur olika synkroniserade vyer tillsammans med egen loggning förklarade ett problem med slumpmässiga omstarter. Utvecklarna misstänkte att omstarterna berodde på att deras ”watchdog timer” löste ut och orsakade omstarten. Men det var oklart varför detta skedde, då timern nollställdes från det högst prioriterade tasket i systemet (här kallat ”SamplerTask”). Eftersom detta RTOS använder strikt prioritetsbaserad schemaläggning, som brukligt, så kan inget annat task avbryta detta. Så vad har hänt?
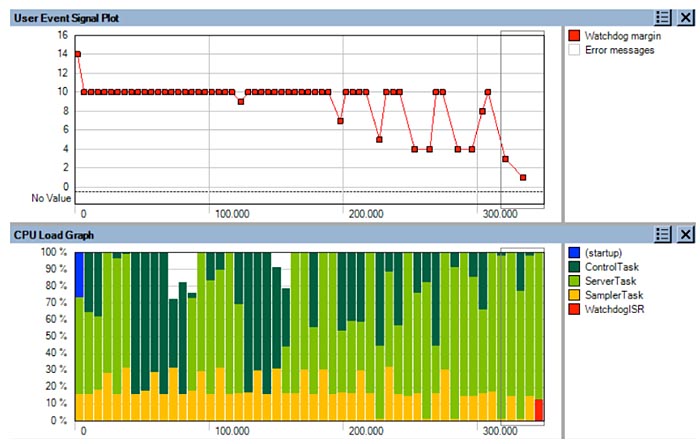
För att bättre förstå beteendet bättre så utökades loggningen med s k ”User Events” i samband med att watchdog timern nollställdes. Där loggades även hur mycket tid som återstod i watchdog timern innan omstart, dvs. ”marginalen”. Eftersom Tracealyzer kan visualisera godtycklig loggad data på en tidslinje (”User Event Signal Plot”) kunde utvecklarna se hur watchdog-marginalen påverkades av systemets beteende och tydligt se vad som orsakade omstarten.
Inspelningen visade även utvecklarna att ”SamplerTask” gjorde andra saker utöver att nollställa Watchdog-timern. Det skickade data via en meddelandekö till ett annat task, ”ControlTask”, som alltså exekverade med lägre prioritet. De kunde se de fördröjda nollställningarna orsakades av att skrivningen till meddelandekön blockerade tasket. Närmare analys i Tracealyzer bekräftade misstanken att berodde på att meddelandekön blivit full.
För att undersöka varför meddelandekön blev full valde man att titta på CPU-belastningen över tiden och jämförde detta med Watchdog-marginalen. Detta illustreras i fig 2, där dessa två Tracealyzer-vyer visas på en gemensam tidsskala. CPU last grafen visar de tre huvudsakliga tasken med respektive färg i prioritetsordning. Det ljusgröna är alltså ”ServerTask”, med medelhög prioritet. Som synes exekverar detta mer i den senare halvan av inspelningen, på grund av yttre stimuli. Detta lämnar mindre processortid över till det lågprioriterade ”ControlTask”, som då inte hinner tömma meddelandekön tillräckligt fort. Watchdog-marginalen minskar och slutligen försvinner helt och orsakar omstarten i slutet av inspelningen. Detta är ett exempel på fenomenet prioritetsinversion (”Priority Inversion”) orsakat av en delad resurs (meddelandekön). Lösningen var att ändra prioritetssättningen så att ”ServerTask” fick lägre prioritet än ”ControlTask”.
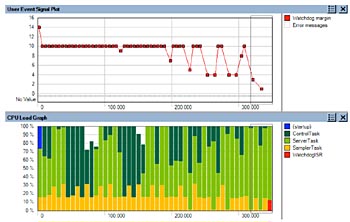
Fig 2: Watchdog-marginalen minskar när ”ServerTask” ökar (klicka för större bild)
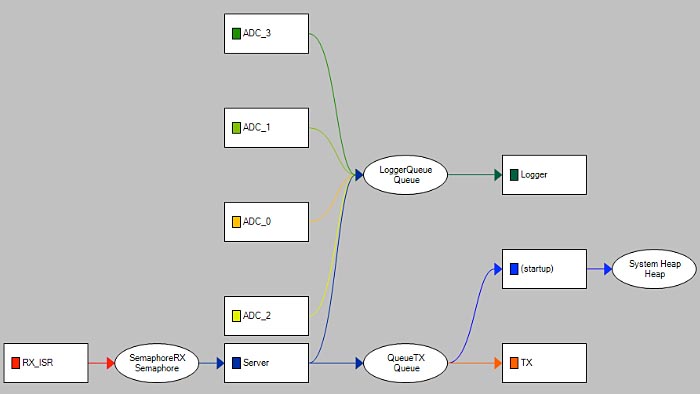
Det tredje exemplet handlar om oväntat försämrade prestanda i ett uppkopplat system. Systemet läste av sensorer och skickade sensordata via TCP/IP. I den senaste versionen noterades att svarstiden, från begäran till skickad data, hade ökat betydligt. Detta trots att kodändringarna var små och till synes irrelevanta för prestanda. Utvecklarna misstänkte att schemaläggningen hade påverkats och genom beroendegrafen ”Communication Flow” (fig 3) framgår att ”Server” skickar data till ”Logger” tasket som uppdaterar en loggfil på hög nivå, orelaterad till Tracealyzer.
Det visade sig att många av ”småändringarna” i koden sedan förra versionen var just utökad loggning, vilket orsakat prestandaförsämringen. Detta då ”Logger” exekverade med högre prioritet än ”Server” och därför orsakade minst två task-byten för varje loggning, förutom att själva skrivningen till loggfilen skedde medan ”Server” fick vänta. Liksom i förra exemplet var lösningen att justera taskens prioriteter, i detta fall så att ”Logger” fick lägre prioritet än ”Server”. Därmed buffrades loggningen i meddelandekön tills ”Server” är färdig, och först då behandlades. Detta minimerade antalet task-byten och förbättrade svarstiden för ”Server” avsevärt.
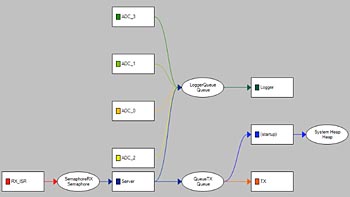
Fig 3: Beroendegrafen visar att ”Server” skickar data till ”Logger” (klicka för större bild)
Sammanfattning
Inbyggd programvara blir allt mer komplex, vilket ökar behovet av bättre utvecklingsverktyg. Även om programvarans beteende kan spelas in på olika sätt, är den resulterande informationen ofta komplex, ohanterlig och svår att dra slutsatser från. Genom innovativ specialutvecklad visualisering, som t ex Tracealyzer erbjuder, blir informationen betydligt lättare att förstå och dra slutsatser från under utveckling testning och optimering. Det är dessutom inte enbart ett labbverktyg, inspelning kan även användas i fält. Genom att inkludera inspelning i produktionskoden kan utvecklare få mycket värdeful diagnostik vid eventuella kundproblem, som gör det enklare att förstå grundproblemet. Inbyggd programvara behöver inte längre vara en ”black box” där utvecklarna måste gissa sig till lösningar. Moderna visualiseringsverktyg öppnar upp systemen och förklarar.
Dr Johan Kraft, CEO, Percepio AB
Johan Kraft är VD och grundare av Percepio AB, som utvecklar visualiseringsverktyg sedan 2009. Johan är teknologie doktor i programvaruteknik och hans forskning fokuserade på praktiska metoder för analys av realtidsbeteendet hos inbyggd programvara, vilket genomfördes i nära samarbete med regional industri. Johan arbetade tidigare med utveckling av styrsystem för industrirobotar.
Filed under: Embedded





{kind=link}
{kind=link}
{kind=link}
{kind=link}