

Optimera FPGA för låg energiförbrukning
Efter flera generationer av FPGA-enheter med all högre densitet och allt fler funktioner måste konstruktörer nu flytta fokus till energiförbrukningen. Chandra Sekar Balakrishnan, systemutvecklare hos Xilinx, visar här hur man kan ta hänsyn till energiförbrukningen från de allra första stegen i konstruktionscykeln.
När transistorernas dimensioner krymper med varje ny generation inom processtekniken tenderar läckströmmen inne i transistorerna att öka. Detta leder till högre statisk effektförbrukning när FPGA-enheten inte är igång. Den dynamiska effekten tenderar också att öka, eftersom snabbare switchegenskaper hos transistorn gör det möjligt att använda högre klockfrekvenser som ökar effektförbrukningen i den de programmerbara logikkretsarna och I/O-enheterna. I och med att FPGA-enheternas kapacitet fortsätter växa med varje produktgeneration ökar mängden logikkretsar, vilket innebär högre läckage och fler transistorer som arbetar med högre hastighet per enhet.
En följd av detta är att konstruktörer måste uppfylla krav på systemeffekt och termiska förhållanden i ett tidigt stadium av FPGA-utvecklingen.
Fig 1 beskriver konstruktionscykeln från val av FPGA-enhet till konstruktionsteknik för lågeffektkretsar. Olika åtgärder kan tas i olika steg av arbetet i syfte att sänka FPGA-enhetens totala effektförbrukning.
Val av enhet
Vid val av FPGA-krets är det viktigt att först göra en utvärdering av processtekniken. Xilinx 7-serie baseras till exempel på 28 HPL-processen (28 nanometer High-Performance, Low-Power), en teknik som minskar läckströmmen och eliminerar behovet av statisk effektreglering i FPGA-konstruktionen. Jämförbara FPGA-enheter som tillverkas med 28 HP-processen har inte nödvändigtvis någon prestandafördel, men kan förbruka mer än dubbelt så mycket statisk effekt.
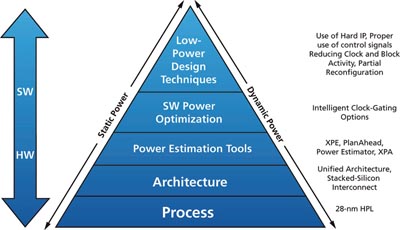
Fig 1. Olika åtgärder kan tas i syfte att sänka FPGA-enhetens totala effektförbrukning, från val av FPGA-enhet till konstruktionsteknik för lågeffektkretsar.
Att gå från en större prototypenhet till en mindre FPGA-enhet för produktion sänker effektförbrukningen effektivt, samtidigt som kostnaden för laserbearbetning m m kan begränsas. Detta kan göras utan större problem vid användning av FPGA-enheter som baseras på en enhetlig arkitektur.
I större system, som vid konventionella konstruktioner kräver flera FPGA-enheter, kan en FPGA-komponent med hög densitet vara till stor hjälp när data behöver flyttas med höga hastigheter mellan separata enheter. Xilinx SSI-teknik (Stacked-Silicon Interconnect) gör detta möjligt genom att aktivera samkörning av flera FPGA-chip som sammankopplas med en kiselinterposer som ger tiotusentals anslutningar. Gränssnittseffekten (bandbredd per watt) kan vara upp till 100 gånger lägre jämfört med ett motsvarande gränssnitt byggt med I/O-enheter och transceiver, medan den högsta tillåtna statiska effekten också är lägre jämfört med enheter av liknande dimensioner på en monolitisk kiselplatta av standardtyp.
Spänningsskalning
Skalning av FPGA-enhetens driftspänning sparar också in både statisk effekt och dynamisk effekt. Utrymmet i 28 HPL-processen gör att 7-serien i varianterna -2L (1,0 V) och -2L (0,9 V) FPGA kan erbjuda mycket låga statiska och dynamiska effektbehov utan hastighetsförluster.
En drivspänning på 0,9 V sänker den statiska effekten med cirka 30 %. Spänningsfallet innebär också reducerade prestanda, men Xilinx väljer ut enheter av typen -2L (0,9 V) och kontrollerar hastigheten och ger även en mer noggrann specifikation vad gäller läckage. Den här avsökningsmetoden sänker effekten med 55 % i ett värsta scenario jämfört med enheter med standardspecifikationen vad gäller hastighet. Eftersom dynamisk effekt är proportionell mot VCCINT², innebär en tioprocentig reduktion av VCCINT en effektminskning med 20 %.
Effektuppskattning och optimering
Det finns en omfattande uppsättning verktyg som hjälper konstruktörer att bedöma krav på termiska egenskaper och på strömförsörjning genom hela utvecklingscykeln. Fig 2 visar hur Xilinx-verktygen stöder de olika stegen i utvecklingsarbetet.
XPower Estimator (XPE) är ett kalkylblad som ger en tidig uppskattning av effektförbrukningen, till och med innan planeringen av konstruktion och implementering har påbörjats. XPE hjälper också till att utvärdera arkitekturen och valet av enheter, och hjälper till att välja lämpliga strömförsörjnings- och termoregleringskomponenter.
Programmet PlanAhead ger en mer noggrann uppskattning av effektfördelning på RTL-nivå. Konstruktörerna kan ange enhetens driftmiljö, I/O-egenskaper och standardmässiga aktivitetsvärden för konstruktionen, genom att använda begränsande värden eller det grafiska användargränssnittet. PlanAhead läser sedan av HDL-koden i syfte att uppskatta vilka konstruktionsresurser som behövs, och rapporterar den uppskattade effekten baserat på en statistisk analys av aktiviteten i varje resurs.
Efter placering och anslutningsplanering kan XPA (XPower Analyzer) ge konstruktören möjlighet att lokalisera de block eller delar av konstruktionen som förbrukar mest effekt, och därmed identifiera de områden där optimeringen ger bäst resultat.
Effektoptimering i mjukvara
XST-verktyget (Xilinx Synthesis Technology) som ingår i ISE Design Suite stöder effektmedveten konstruktion genom att möjliggöra optimering av logikkretsar för makrobearbetning på block som exempelvis multiplikatorer, adderare och RAM-block. Användning av alternativet –power yes minimerar antalet samtidigt aktiva RAM-portblock. Ytterligare ett steg som kan tas när tidsvärdena hos anslutningsvägarna inte är kritiska, är att forcera användning av den mest effektiva mappningen av RAM-block oavsett hur detta påverkar prestanda.
Användning av Area Optimisation-läget i XST kan också spara effekt genom att minimera antalet resurser som används, även om detta kan innebära sämre prestanda.
Aktivitetsmedveten optimering, eller intelligent grindstyrning genom XST-systemets mappningsalternativ –power high, kan sänka kärnans totala dynamiska effekt med över 15 %. Dessa algoritmer analyserar de logiska ekvationerna per klockcykel i syfte att identifiera register som inte bidrar till resultatet. Fininställda grindstyrningssignaler används sedan för att neutralisera switchningsaktiviteter som inte används.
Användning av kapacitansmedvetna optimeringar ger också värdefull effektbesparing. Det finns två huvudmetoder för detta:
* Gruppera klocklaster: Den här processen styrs av mappningssystemets –power on-alternativ, och omorganiserar placeringen av synkrona element, och sänker kärnans dynamiska effekt genom att reducera både klockresurserna och buffertbehoven.
* Gruppera datalaster: Den här algoritmen är också aktiverad vid mappningssystemets –power on-alternativ, och minimerar den totala kabelledarlängden genom att placera relaterad logik i nära anslutning, samtidigt som prestandakraven uppfylls.
Automatisk avstängning av transceivrar som inte används, faslåsta kretsar, digitala klockhanterare och I/O-enheter rekommenderas. Enheterna i 7-serien eliminerar dessutom läckage från oanvända RAM-block genom att tillåta effektgrindstyrning så att endast det instansierade RAM-blocket strömförsörjs.
Teknik för lågeffektkonstruktion
Det finns många konstruktionstips och tekniker för att minimera effektförbrukningen i en FPGA-konstruktion. En reducering av logiken i konstruktionen där detta är möjligt är avgörande, till exempel genom användning av dedikerade maskinvarublock i stället för att implementera samma logik i CLB (konfigurerbara logikblock). Detta reducerar det totala antalet transistorer och gör det möjligt att använda mindre enheter, vilket leder till lägre statisk och dynamisk effekt.
En allmän regel är att anslutna resurser skall användas i så stor utsträckning som möjligt. Dessa kan styras individuellt, eller som en grupp, i riktning mot FPGA-väven eller kiselresursen. Xilinx CORE Generator är ett verktyg som kan hjälpa till att anpassa dedikerad maskinvara för instansiering av en specifik resurs.
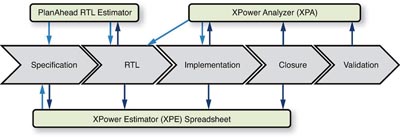
Fig 2. Olika Xilinx-verktyg hjälper konstruktörer att bedöma krav på termiska egenskaper och på strömförsörjning genom hela utvecklingscykeln.
Konstruktörer kan överväga användning av oanvända hårda IP för alternativa uppgifter. Ett exempel är användning av DSP48-block som multiplikatorer, adderare/ackumulatorer, wide logic-komparatorer, skiftare, mönstermatchningsenheter eller räknare, eller användning av RAM-block som tillståndsmaskiner, matematikfunktioner, ROM-minnen eller logiksöktabeller (LUT – wide logic lookup tables).
Optimera styrsignaler
Tilldelning av styrsignaler för synkrona element som klocka, verkställning (set), återställning (reset) och klockaktivering kan påverka enhetens densitet, nyttjandegrad och prestanda. Ett fåtal riktlinjer hjälper till att minimera effektpåverkan.
Användning av både ”set” och ”reset” på ett register eller en latch bör undvikas, eftersom den underliggande vippan endast kan implementera ett av kommandona ”set”, ”reset”, ”preset” eller ”clear” åt gången. Ytterligare styrsignaler förbrukar extra FPGA-logik.
Styrsignalerna skall vara aktivt höga där detta är möjligt. Aktivt låga signaler kräver invertering som förbrukar en LUT-ingång och därmed kan öka runtime-värden och sänka enhetens nyttjandegrad. Om det inte går att undvika aktiv-låg polaritet skall inverteringen utföras i kodens hierarkiska toppnivå.
Reducering av onödig användning av kommandona ”set” och ”reset”, som förhindrar logikstrukturer som skiftregister/LUT-kretsar (SRL-kretsar), LUT-RAM-minnen och RAM-block från att anslutas, kan hjälpa till att förbättra placeringen, öka prestanda och sänka effekten. Många kretsar kan fås att självåterställas utan att någon ”reset”-funktion behöver användas.
Användning av BUFGMUX, BUFGCE och BUFHCE för grindstyrning av en hel klockdomän hjälper till att optimera klockans och blockets aktivitet. För applikationer som bara pausar klockan på små ytor i konstruktionen kan klockans aktiveringsstift (clock-enable) i FPGA-registret användas.
Andra tips innefattar placering av logik som används oregelbundet i en enda klockregion för att förhindra att konstruktionen breds ut över flera klockregioner. Verktygen försöker utföra detta automatiskt. Vissa konstruktioner kan kräva manuella insatser. Vi rekommenderar även steget att begränsa datarörligheten runt FPGA-enheten genom färre och kortare bussar, samt noggrann placering av stift och motsvarande logik under ytplaneringsstadiet.
Partiell omkonfigurering
Effektiv användning av partiell konfiguration kan spara in både statisk och dynamisk effekt. Konstruktörerna kan i princip skapa tidsintervall inom enheten och därmed använda en mycket mindre FPGA-enhet (och spara statisk effekt). Dynamisk effekt kan sparas in genom steget att byta ut en högprestandaenhet mot en lågeffektversion av samma typ.
På liknande sätt kan I/O-enheter omkonfigureras, till exempel vid konvertering av effekthungriga LVDS-I/O-enheter till gränssnitt med lägre effektbehov, t ex LVCMOS (i de fall då tillämpningen tillåter detta). I vissa konstruktioner uppgår I/O-effekten till halva totaleffekten, särskilt i minnesintensiva system.
Lågeffektstandarder för I/O, t ex HSLVDCI, kan innebära betydande effektbesparingar vid kommunikation mellan flera FPGA-enheter, och i minnesgränssnitt som arbetar med lägre hastigheter. Optimering av slew rate och drivningsstyrka, samt användning av DCI-kretsar (Digitally Controlled Impedance) minimerar också effektförbrukningen vid FPGA-termineringar.
Transceivereffekt
Xilinx 7-serie FPGA-transceivers erbjuder lågeffektlösningar som innefattar en delad LC-faslåsningskrets, och en fyrvägs-PLL för fyrvägskonstruktioner. Andra effektiva effektbesparande metoder innefattar val av lägsta möjliga PLL-arbetsområde, aktivering av TX/RXPOWERDOWN-alternativ individuellt, samt aktivering av PLL-frånslag i lägsta effektläget.
Redan från början
Förståelse och implementering av teknik för effektkänslig konstruktion, innan programmeringen påbörjas, är den mest effektiva rekommendationen för att sänka systemeffekten. FPGA-konstruktionsverktygen ger också många funktioner som hjälper till att uppfylla effektspecifikationerna, och tillhandahåller information som ger kretskortskonstruktörer möjlighet att optimera konstruktionen av strömförsörjningskretsar.
Chandra Sekar Balakrishnan, systemutvecklare, Xilinx
Filed under: EDA




